Launch of the new iRail
Hi all!
Last week we launched the new iRail. It was among other projects, like the rework of the open Summer of Code website, one of the things I was able to work on these last eight weeks as an intern at iRail/Open Belgium.
In this post, I’d like to talk about the new iRail and what makes it so cool. Aside from the visual refresh, we’ve made a few functional additions below the hood of the application that allow us to do really awesome things in the future.
Visual overhaul
But let’s start at the beginning, shall we? The new iRail has been given a visual overhaul — it should be easier to use on the desktop, and on mobile as well. You’ll have to do a little more scrolling on mobile, but now we can avoid those nasty, long list boxes; you can now easily select the date and pick a date without having to use a dropdown. Especially when viewing found routes, your experience should be better than the previous version.
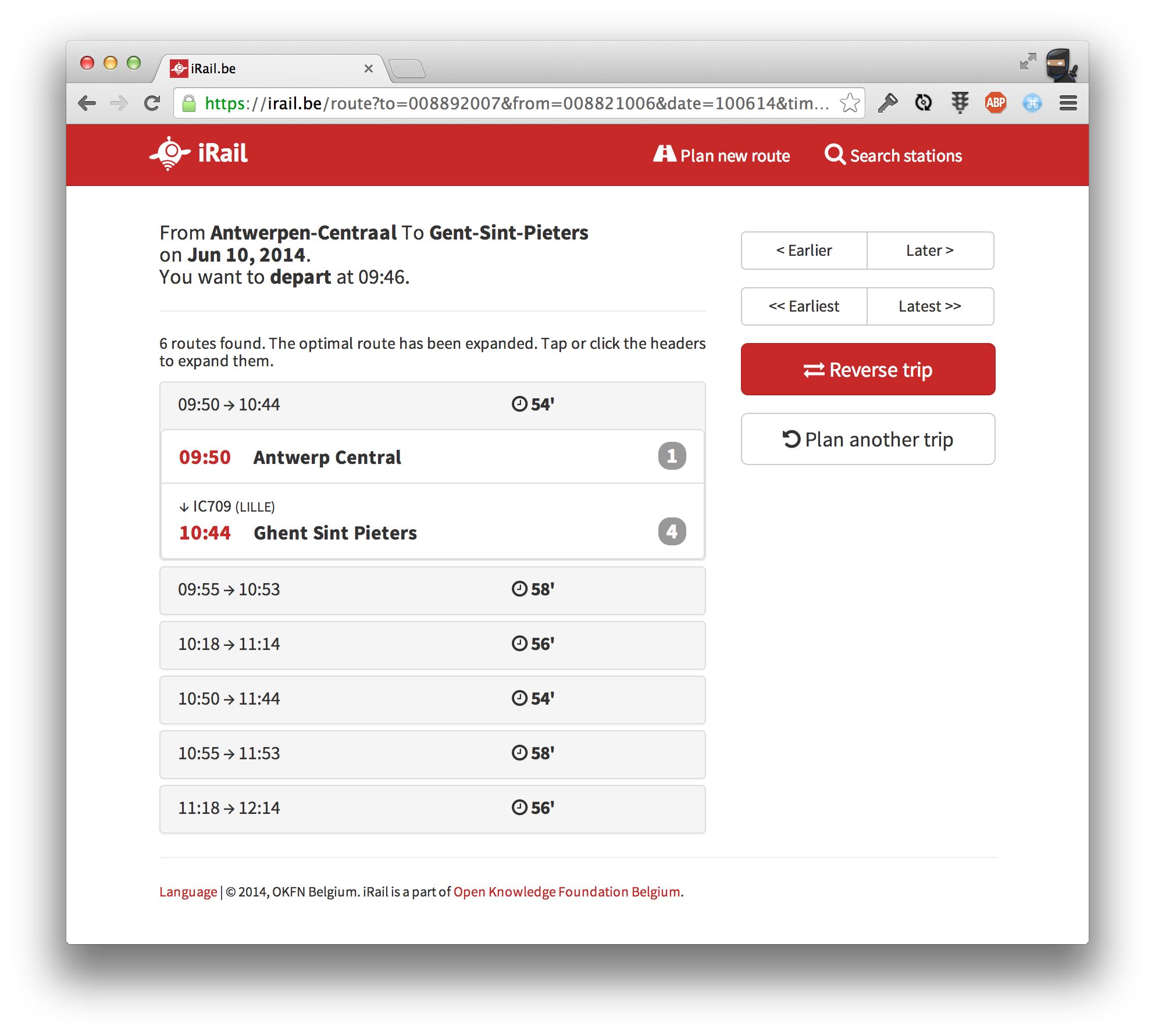
What the new iRail looks like
Performance
Performance wise, the app should perform at about the same speed; we’re doing some cool stuff behind the scenes to archive and transform the data as well, so if the app is any slower than usual, it’s because of this.
Under the hood
So, what have we changed under the hood? We’ve integrated the API on irail.be. If you make a regular request to, say, ‘http://irail.be/route‘, you’ll get the page you’re familiar with in your web browser. However, if you plan a route and make a request with accept headers set to return ‘application/ld+json’, you’ll receive JSON data instead of raw HTML.
Linked data
The fact that we’re providing JSON-LD means we’re using linked data. All departures you can find on the liveboards are actually linked to unique URLs that can be copied and referenced. What’s cool is that all departures are logged on archive.irail.be, so if the departure you linked is no longer on the liveboard, the data is still available via archive.irail.be, and we’ll show it to you, but with a twist!
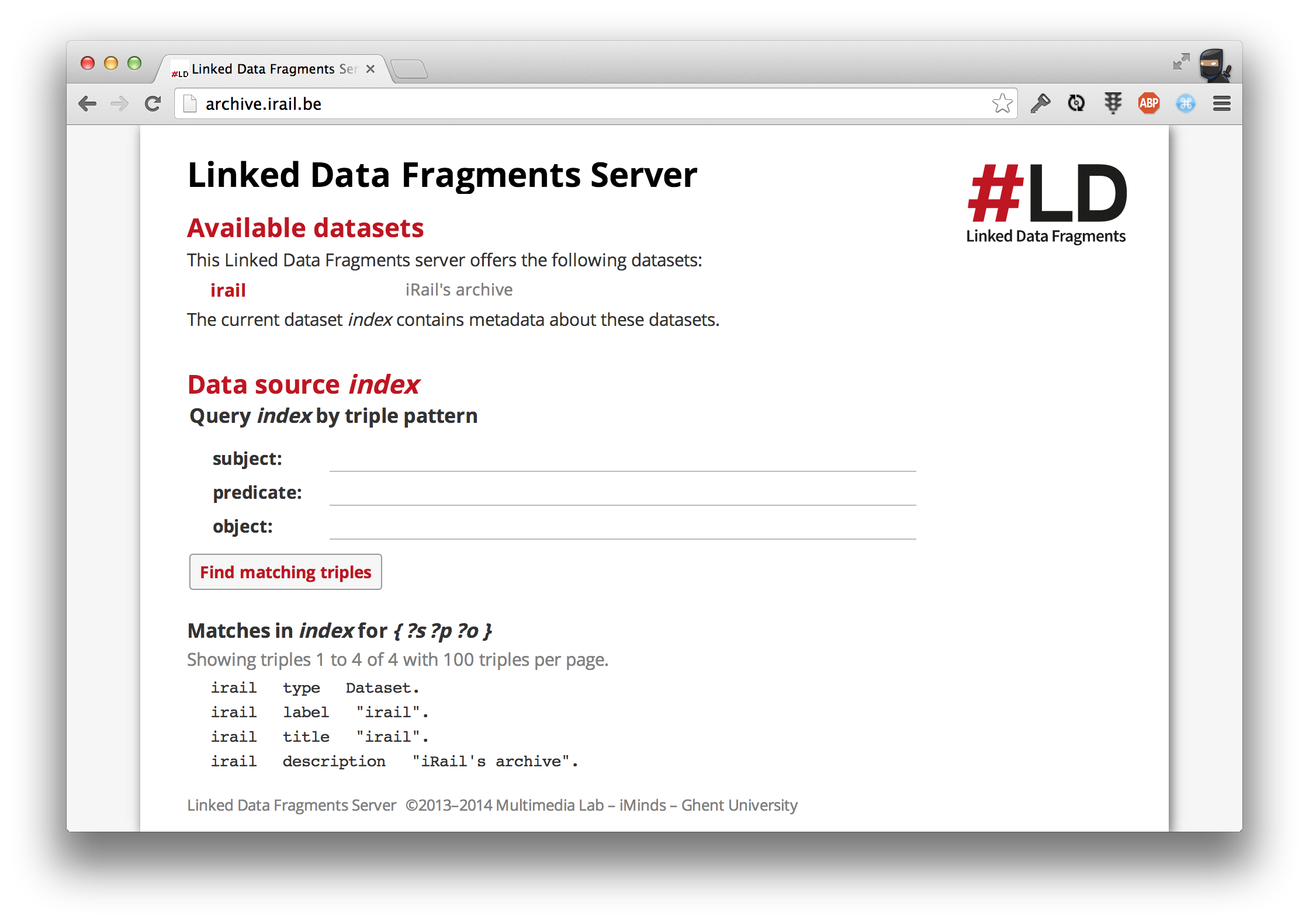
archive.irail.be runs a linked data fragments server
Since we archive data at regular intervals, you might notice we can list the historical delays. That’s useful now, but the potential of this system is revealed in time: the more data we have, the more stats we can derive from the data; which trains had the most delays? What is the average delay? These questions can be answered (in time)!
Anyway, we hope that you enjoy the new iRail. And of course, any feedback you might have is welcome. All our source code is available freely on GitHub, so feel free to open an issue if you have feedback. If you’d like to contribute, we love pull requests as well.
I really hope you enjoy the new iRail as much as I enjoyed my internship (which is to say, a lot)!
And of course, don’t forget to spread the word (@irail)!
Nico