One million daily requests: where do they come from, and how we’ll cope with them
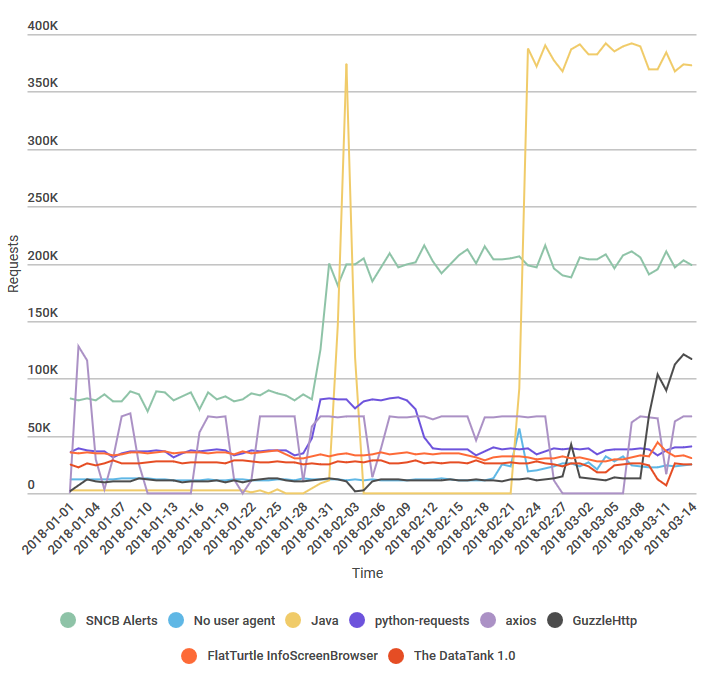
Since improving iRail server performance back in October, the iRail servers have been serving everyone without any major issues. The servers handled around 300.000 requests every day, which left quite some margin. Back then, we estimated the server capacity at 1 million request per day.
Today is that day. Our server monitoring alerted us of increasing CPU usage, and we found the origin: we’re now serving over 900.000 requests every day. Due to the fast increase in the number of requests, where half of the requests are coming from only one IP address, we temporary started enforcing stricter rate limiting, meaning that instead of 5 requests per second, only 3 will be allowed. This shouldn’t affect you, but if it does, please get in touch with us to work out a solution.
In order to know where requests are coming from, and how this evolved over time, we analyzed log files from the past 74 days. After analyzing the 18gb of data, I decided to created an infographic. This way everyone can see the current state and how we evolved. It’s interactive, so you can enable or disable any client by clicking it in the graph legend.
Why clients use iRail
Most of the clients can be grouped into one of three categories:
- Routeplanning applications for users
- Digital signage, applications meant to be shown on TVs to inform people passing by of nearby public transport departures
- Gathering information on delayed trains
The first one is a smaller category, which need an API like iRail. The second category also needs an API, but is more specific: they usually just need the departing trains for one or more nearby stations the next hour or two. The last category is different compared to the previous two: they need data which isn’t available through an API requests. In most cases they need to resort to loading the departures for all stations over and over again. This means they need a lot of requests (about 600) to update their information, which takes 2 minutes when obeying the old rate limiting system. Using the stricter rate limiting rules, this will take three to four minutes.
Linked Connections
It’s clear we need to do better. therefore, we can proudly announce that we’re currently beta testing Linked Connections, a brand new way of publishing transport data. Our new linked connections API will publish a list of all departing trains in Belgium, sorted by departure time.
What does this mean for you?
- Offering users a routeplanning app? You will be able to implement your own route planning and support offline searches. As always, we’ll publish some open-source examples so you don’t have to figure it all out on your own. Does this sound scary to you? We’ll keep providing a traditional API.
- Wanting to show the next departures? Just load the list for the time period you want to get the departures for, and filter out the departures at the station(s) you’re interested in. Again, we’ll provide some open-source examples and we’ll keep providing a traditional API.
- Want to retrieve all delays? This category is the big winner. Just load the list for an hour or two, which is about 12 requests. That’s 50 times less requests!
The new API will serve the same list to everyone, meaning that with 1 million daily requests, you’ll have between 80% and 90% chance to hit a cache. Caching means we can serve more requests and we can server them faster – this also means rate limiting will be quite loose (around 10 requests per second, or more), so you can refresh your data often enough.
A few last words
Creating this infographic was only possible thanks to the user-agents included in the requests. However, still 5 of the top-8 clients don’t include a clear user agent. This means that we could not inform them of the new stricter rate limiting, or other updates to the iRail API (We only included the application name in the infographics above).
If possible, set the user-agent header string. Include the name of your application, and a way to contact you in case something would go wrong. An example user agent string format is <application name>/<application version> (<website>; <mail>)
, which could result in the following string: irail/1.2.0 (irail.be; hello@irail.be). The use of a user agent string like this isn’t obligated or enforced, but definitely allows for better communication.
Do you have a great concept?
If you have a great idea which needs railway data, you can instantly get started with our free to use API. You can find all information on our API at docs.irail.be. Want to analyze data yourself? We’re publishing API logs and occupancy logs at gtfs.irail.be.
Stay up to date by following us on twitter, joining our gitter channel, or make sure to follow this blog.
Open data for stations and accessibility
While the iRail API has been getting quite some updates, we remained silent about our open data on stations. Mostly because there wasn’t really anything to talk about. Today is different.
What we had before
Before today, we provided a list of stations, with their ID, translations, coordinates and ‘importance’ (e.g., Brussels West would be less important than Brussels South). While this enabled a lot of people to create nice things, it isn’t enough. In the past, we’ve received questions about station addresses, and at UGent, research is being done to plan routes keeping accessibility and disabilities of travelers in mind. We didn’t have this data, while it’s clearly valuable.
And what we offer now
We have created a scraper to scrape every station page there is, based on our existing stations.csv file. The results are stored in facilities.csv. The following data is now publicly available:
- Address of the station
- If ticket vending machines are present
- If luggage lockers are present
- If there is free parking, taxi, bicycle parking, taxi, bluebike, bus, tram, metro
- If there are wheelchairs available,
- If there is a ramp to roll wheelchairs on a train
- If there are parking spots reserved for people with a disability
- Whether or not the platform is elevated, if escalators are present up and/or down, if there is an elevator on the platform
- If there is a hearing aid signal
- Opening hours for ticket sales
All code and data is open source in the irail/stations repository.
Now go create something awesome with it!
More API data in less network data
Days are getting shorter, and iRail API responses are getting longer. We’ve added some more data to various API endpoints, so you can build even better applications. We’ve also improved support for HTTP caching, and are closing in on a release for LinkedConnections. Let’s check it out!
Route data
For a while, we weren’t able to provide the status for trains in a connection. We didn’t have that data, and we were at peace with it. But everything changed when the NMBS decided to delete a file from their site. Our status monitoring told us we were in trouble a minute or two later. It was the endpoint we were using to query connections, and now that it’s gone, we had to get our data somewhere else. With tens of thousands daily API requests, we’d also better fix it fast. I continued a previous investigation into the NMBS mobile app API. Quickly I was able to figure out how it worked, and we were able to get the API back online within 4 hours and 19 minutes. Within a few days the new code was mostly bug-free, and any bugs in the last weeks were quickly fixed, thanks to the help of some other developers who were happy to assist.
With this bad news also came some good news. While the old endpoint didn’t provide data about trains arriving and leaving the next station in your route, the new one does. Therefore, we are now able to provide you with the left and arrived status of trains in a connection. Make something beautiful with it.

Example usage of the left and arrived attributes in the open-source Hyperrail application

Example usage of the walking parameter
We also have alert data, pin-pointed to specific parts of the route. This way end-users can be even better informed about where in their journey they can come across some hinder. In order to demonstrate what’s possible with this new data, I’ve taken some screenshots using the Hyperrail for Android application which is already update to use these parameters.
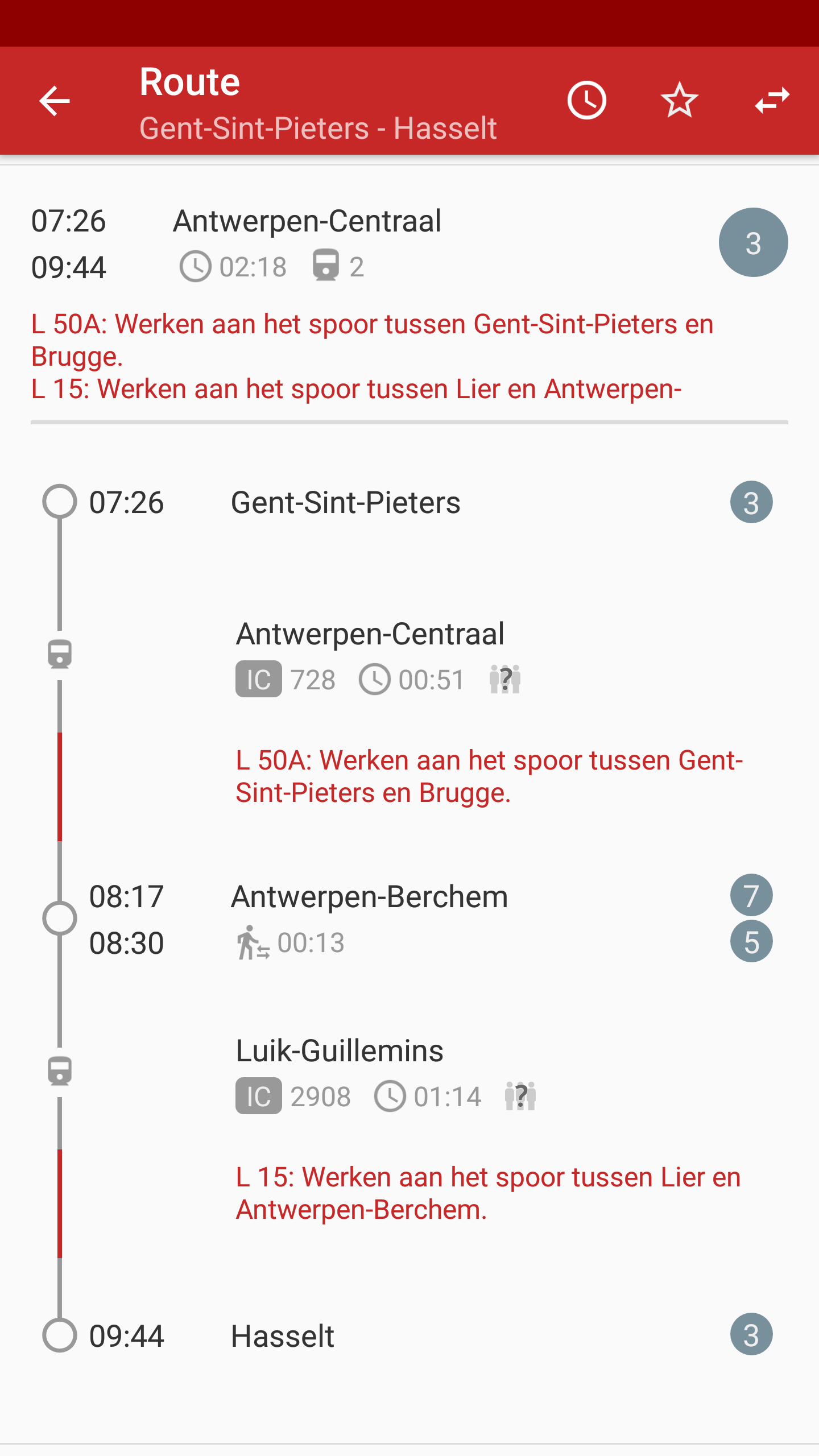
Example display of alerts
Last but not least, there can now be walking parts in a route. This is rare, but in some cases it’s necessary, for example when travelers get off at Haren but need a next train at Haren-zuid, which is within walking distance, without any trains connecting those two stations.For the techies: a new attribute ‘isWalking’ has been added to every departure/arrival of a connections object. This way you can easily distinguish those routes. Just don’t try to parse a train or destination for those walking parts, but you can read all that in our documentation.
Vehicle data
I’ll keep it short here: You can now see if a stop is part of the ‘normal’ route of this train, or if it’s an extra stop which was added last minute by traffic control.
Log and feedback data
All iRail API log data, and spitsgids feedback, is now automatically published on gtfs.irail.be every morning at 3:00. This way everyone can instantly make use of the most recent spitsgids data. Feel free to scrape this site if you need data for multiple days. The formats are documented in the API documentation.
Conditional get requests
A 304 Not Modified response signals you can just keep using the last data you have
The API supports caching and conditional get requests. Conditional get requests allow you to tell the server which version of the data you have. If there is newer data available, the server will return an HTTP 200 status code along with the new data. If no new data is available, the server will return an HTTP 304 Not Modified status code, along with an empty body. We only support the if-none-match header for now, with more details in the docs.
What’s next
Having all these new fields doesn’t mean we’re done here. We’ve almost gotten LinkedConnections ready for production, and we’ll be opening up a lot of data about stations and their accessibility. Make sure to follow @iRail on twitter to stay up to date!
You can read all of this over in the documentation, view the iRail API code on github, or view my Hyperrail source code on github. View our data dumps at gtfs.irail.be.
iRail server move and bugfixing
Hi,
I’m Bert, a 21 year old student at Ghent University. I came into contact with iRail when I fixed an existing but broken application to view realtime train data on Qt devices (mostly for Nokia’s Symbian OS). A few years back I ran into Pieter again at Open Summer of Code, and I’ve been contributing to various iRail projects since. Last week I started a 3 week student job to fix issues with the API, improve performance and move servers. In the meanwhile, I’m testing with my own Hyperrail Android application.
In the past week we have been rather busy setting up a new server for the iRail project. This new server will handle all API requests and all requests to irail.be. While moving servers, we also tried to optimize the code in order to get faster API responses – with success. Response times dropped from between 500 and 5000ms to an average of 250ms. I’ll try to explain what changes were made, and how they affect the API.
Caching requests
Requests from our scraper to the NMBS website are now cached, meaning that every response from the NMBS is kept in memory for 15 seconds. Especially the liveboard endpoint is impacted by this, as most requests for big stations will be able to use cached NMBS data. By caching inflatable water slide at the NMBS data level, the cache isn’t affected by the requested output format (xml or json), resulting in more hits and faster responses.
Caching station lookups
A while ago, the `&fast=true` parameter was introduced to produce faster responses. When this parameter was supplied, station names received from the NMBS would be passed on to the clients without looking up station ids or standardizing the name. This resulted in faster queries, but this only addressed the symptoms, instead of the cause.
By caching the station lookups (where a station name from the NMBS is looked up in stations.csv and all information is returned), the time required to look up a station almost dropped to 0. Furthermore, the number of stations is limited, and this data doesn’t change. This means that once a station has been cached, it doesn’t ever expire (unless data is updated manually). As a result, within the first 100 queries after starting PHP, all big stations will be cached, and further requests won’t have cache misses. At this moment, the `&fast=true` parameter no longer affects the speed, as the station lookups are instant now. A comparison of tests with and without station caching can be found in Github issue #111.
Bug fixing
Spitsgids
Spitsgids has had a round of bugfixing. Some issues with posting data, and some with viewing the occupancy for trains have been resolved.
iRail API
Not only spitsgids, but also the API got its round of bugfixes. As a result, the API should be more reliable. Most important here are some changes to the vehicle endpoint. The name field will now always be formatted as “BE.NMBS.xxxxx” where xxxxx is a train id as used by the NMBS (like IC817, S51245, …), and a shortname, which is just the id as used by the nmbs (for example IC817). Earlier, the name field contained the id which was passed in the url. If you build applications on top of the iRail API, be sure to test if this doesn’t break your application and update your application if necessary.
Furthermore the connections endpoint includes some additional information: vias not only include the direction and id of the train arriving in this via, but also the direction and id of the train which leaves at this via station. This should allow to use the API more easily, and should help in building applications which post data to spitsgids.
New documentation and uptime monitoring
In the past, users notified us whenever the API broke down. From now on, all API endpoints are monitored and notifications are sent out when one of them goes offline. Everyone can check the current status on status.irail.be.
The documentation which was previously hosted on our blog got outdated over time, and wasn’t as clear as it could be. Therefore, the documentation has been rewritten, and is available on docs.irail.be, is available on github.
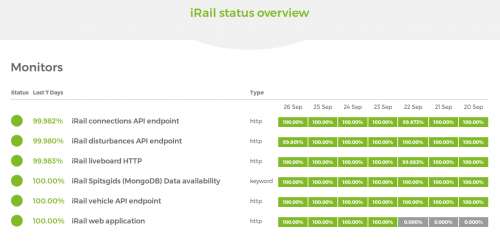
Our uptime monitoring
Up next
I’ll be working 2 more weeks on the iRail project. During these weeks I’ll work on the definition of good URIs as identifiers, and on the use of LinkedConnections data as data source for the iRail API. I’ll try to fix as many issues for the iRail API and spitsgids as well.
A special thanks goes out to Ghent University: they’re funding my work during these three weeks so volunteers can work more efficiently on iRail, and I will look at better publishing mechanisms for transport data. This way we can make sure we can keep accessing the valuable research data.
Official GTFS real-time feeds available for SNCB
As of today, you can request the official GTFS real-time feeds of SNCB! This is great news: our real-time feeds were only a scraped version of what was announced on their websites. If you now want to rely on a high-quality data feed of train disturbances and train delays, you can rely on their new feeds. Request this over here:
http://www.belgianrail.be/nl/klantendienst/infodiensten-reistools/public-data.aspx *
With iRail, we are allowed to use the GTFS data within our API and redistribute it. We slowly migrate our datasets to use this new data. Someone in for a day of hacking?

* You still need to sign a contract and thus cannot call this open data just yet.