Open Belgium 2017: the state of Open Transport Data
Tomorrow it’s the Open Belgium 2017 conference. We are hosting a session on the state of play of Open Transport Data in Belgium. We look forward to welcoming Arnaud Wattiez from SNCB, Sébastien Goffin from STIB and Bert Van Hemelen of De Lijn, who each will give a presentation on their recent activities and plans on the Open Data domain. Afterwards, Peter Defreyne (Antwerp Management School) and I will ask questions to the panel to discuss the next steps.
Of course, many of these datasets are also available through the iRail API under the CC0 waiver, or through our unofficial GTFS dumps at gtfs.irail.be. We are only a third party that gives out data without warranty and can not guarantee sustainability (we are online for 9 years this year though). Whether iRail is legal remains in the gray zone for the time being: we believe there is no sui generis database law applicable on the data. However, much depends on the intention of the public transit companies themselves as well: do they want to stimulate their data to be picked up for maximum reuse? The quality of the open data would raise tremendously when the transport companies would publish official Open Data.
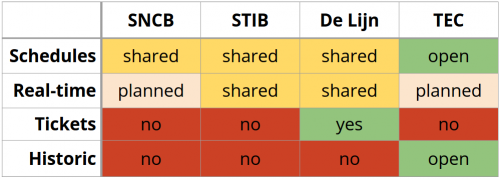
State of Open Transport Data in Belgium in 2017
The TEC
After all this time, I’m still impressed with TEC. They are not going to be at Open Belgium 2017 tomorrow. They said: “we will not be able to tell you something new after being at Open Belgium 2014 and 2015”. They provide both historic dumps as their currently planned schedules for entire Wallonia. Providing historic schedules is very relevant for e.g., mobility studies: how is the mobility of a certain area evolving? This is not possible at any of the other data providers.
In each case, TEC gots it right with http://opendata.tec-wl.be/. With its simple and pragmatic Open Data portal, it is a frontrunner in Belgium for a couple of years now. They also have plans to open up their real-time datasets.
Shared data
You can request access to the files of SNCB, STIB and De Lijn, to both the planned files as to the real-time data (at least, soon to come with SNCB). In each of the cases, a non-open contract needs to be signed. There we call this data sharing, and not Open Data. Apart from their licenses not being compliant to the Open Definition, we can also see practical issues with this data for use within a Web ecosystem: when added to an open data portal, it cannot directly link a machine to the files.
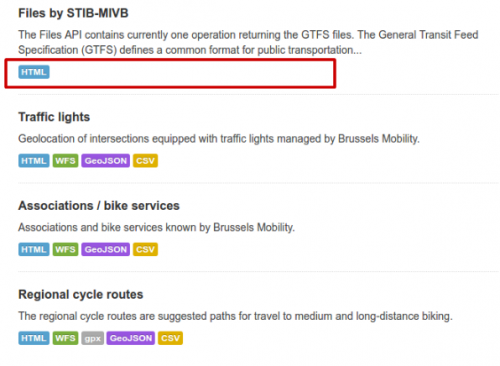
The MIVB-STIB datasets do not contain a link for machines to the data directly from the open data portal of Brussels
Next, we also do not want transport agencies to open up an API for e.g. real-time data. We want them to share the raw data files needed to create APIs. APIs are often rate-limited, which defeats the purpose of maximum reuse and rewarding successful third parties. When real-time data needs to be shared, a couple of files that update each 30 seconds is still easy to host and provides the flexibility to third parties to implement any use case, instead of being heavily tied to the functionality an API exposes. The MIVB-STIB at this moment have the most complex system to reach the data itself, with API keys and rate limits on top of simple data files.
Open Ticketing
Yesterday, the news broke the SNCB is giving a monopoly to Olympus Mobility on their ticket reselling. Also with iRail we already requested access to reselling tickets, as this is the only feature why people still use the SNCB app over apps like Railer or BeTrains. Alexander De Croo, who also will be speaking tomorrow, agrees with us: open data reusers should become partners in ticket selling instead of competitors. Tomorrow, we will ask Arnaud Wattiez from SNCB to elaborate on this: are there plans to give others access to ticket reselling, just like De Lijn is already doing?
Mensen moeten makkelijk snelste traject kunnen vinden en tickets kunnen kopen. NMBS en innovatieve mobiliteitsapps zijn bondgenoten. https://t.co/NopnfNJL6L
— Alexander De Croo (@alexanderdecroo) March 4, 2017
In each case, tomorrow will be a day where we will learn a lot about the future of Open Transport Data in Belgium from the transport companies themselves. See you there!
open Summer of code 2017
You probably know we’re organizing, since 2011 already, open Summer of code, where we hire up to 30 students to work on open source projects.
Today, we’re looking for students to hire! Thanks to OASIS, a 50% grant from the European Commission Open Knowledge Belgium received, we will be able to hire a small team of students this year again on predicting how busy your train will be.
The current status of our occupancy predictions are explained at https://irail.be/app or in this talk:
To that extent: if you’d be a student willing to join this team, we’re still looking for a front-ender/UX-er, looking for a transport scientist, a back-ender and maybe someone who want to take the lead on the communication strategy.
At #oSoc17 we will hire students to work on #spitsgids user experience and data analytics – interested in this job? https://t.co/F52clSX9Zs
— iRail (@iRail) February 4, 2017
If you would be a company who would like to support iRail financially (we still only have 50% of the money needed for this team), please let us know as well! We’d love to talk to you whether we can add something that also suits your needs.
Call for Speakers: Open Belgium 2017 conference
Open Knowledge Belgium has a yearly conference called Open Belgium! In 2017, the Open Belgium conference will be held in Brussels on March the 6th. Today, the call for speakers was announced!
As this is a yearly tradition for iRail as well to host a session as well, we would love to know who’s interested in participating in summing up the state of the art of Open Transport in a break-out room. Anyone?
The first month of collecting occupancy scores
It has now been one month since we soft-launched the iRail occupancy features of Spitsgids. From then on, it would be possible for commuters, to indicate how busy their train would be. Of course, we would not be iRail if we would not give this back to the community: you can not all start working with this data, as we published all the feedback we got until now (about 1400 entries) in 1 file:
<blink>Get it while it’s hot! http://gtfs.irail.be/nmbs/feedback/</blink>
This evening, Monday the 10th of October, we are pitching this new dataset as a resource for people at the Ghent Data Dive on mobility data. The challenge entails to use this data to predict the future. Now that we now for sure how busy certain trains were, we want to predict how busy certain trains will be in the future, by using various different datasets, such as the iRail query logs, the weather data of KMI/IRM, buienradar, Uitdatabank, etc.
Soft-launching occupancy scores in the API
Hi all,
In May 2016, TreinTramBus and iRail successfully finished a crowd-funding campaign called Spitsgids, in which we were able to raise €4140 from 121 believers. We promised to hire students during open Summer of code 2016 and to open up the data through the iRail API. Today we are proud to announce the beta launch of occupancy rates in iRail!

What does a beta launch mean?
We have launched the API in production, and apps can integrate the score and can provide us with feedback. The feedback is opened up as open data in realtime under a CC0 license at https://api.irail.be/logs. For the time being, we have 4 occupancy levels instead of 3: high, medium, low and… unknown. Unknown means that we would like to invite the user to give us feedback about this train as we could not make a prediction at this time. We will keep the ‘unknown’ until we have gathered enough data. In the meantime, everyone can start using and reusing the data!
What features are we still going to implement?
Two important features still need implementation. To start with, we want to ‘transfer’ the occupancy from user feedback to the next connections on the line, based on assumptions about how occupancy evolves in a train. We already have a theoretical framework about how this should function, but the technical stuff still needs to be done.
Aside from that, and even more important, the API should learn to make predictions from user feedback. From that, it could learn about structurally busy trains, but also about more exceptional events, like festivals or when the weather is nice and everybody wants to go to the sea. This would be the real power of crowd-sourced information, and it would enable people to plan their journeys in more comfort.
If you think you can help with that, do not hesitate! Also, the more feedback you give about your train, the better!
Kind regards,
Arne, Stan, Serkan and Pieter